With all the holiday shopping happening around now, you probably have visited the websites at Target and Walmart, and maybe that prime Seattle company too. What you probably haven’t visited are two subsidiary sites of the first two companies that aren’t selling anything, but are packed with useful knowledge that can help IT operations and application developers. This comes as a surprise because:
- they both contain a surprising amount of solid IT information that while focused on the retail sector have broader implications for a number of other business contexts
- they deal with many issues that are at the forefront of innovation, (such as open source and AI) not something normally associated with either company
- both sites are a curious mixture of open source tool walkthroughs, management insights, and software architecture and design.
- many of the posts on both sites are very technical deep dives into how they actually use the software tools, again not something you would ordinarily think you could find from these two sources
Let’s take a closer look. One post on Target’s site is by Adam Hollenbeck, an engineering manager. He wrote about their IT culture: “If creating an inclusive environment as a leader is easy for you, please share your magic with others. The perfect environment is a challenge to create but should always be our north star as leaders.” Mark Cuban often opines on this subject. Another post goes into details about a file analysis tool that was developed internally and released on open source. It has a user-friendly interface specifically designed to visualize files, their characteristics, and how they interconnect.
Walmart’s Global Tech blog site goes very heavy into its AI usage. “AI is eliminating silos that developed over time as our dev teams grew”, Andrew Budd wrote in one post, and GenAI chatbot solutions have been rolled out to optimize Walmart’s Developer Experience, a central tool repository. There are also posts about other AI and open source projects, along with a regular cyber report about recent developments in that arena. This is the sort of thing you might find on FOSSForce.com or something like TheNewStack, both news sites.
Another Walmart article, posted on LinkedIn, addresses how AI is changing the online shopping experience this season with more personalized suggestions and predictive content, (does this sound familiar from another online site?) and mentions how all Sam’s Club stores have the “just walk out” technology that was first pioneered by Amazon. (I wrote about my 2021 experience here.)
One other point: both of these tech sub-sites are not easily found: tech.target.com (not to be confused with techtarget.com) and tech.walmart.com — have no link from either company’s home pages. ” I’m not sure these pages should be linked from the home pages,” said Danielle Cooley, a UX expert whom I have known for decades. “As cool as this stuff is for people like you and me and your readers, it’s not going to rise to home page level importance for a company with millions of ecommerce visitors per day.” But she cautions that finding these sites could be an issue. “I did a quick google of ‘programming jobs target’ and ‘cybersecurity jobs target’ and still didn’t get a direct link to tech.target.com so they aren’t aiming at job openings. But also, the person interested in cybersecurity will not also the person interested in an AI shopping assistant for example.” Given their specificity, even if a visitor lands on them, they still might go away frustrated because the content is pretty broad.
You’ll notice that I haven’t said much about Amazon here. It really isn’t fair to compare the two tech sites to what they are doing, because of Amazon’s depth in all sorts of tech knowledge. And to be honest, in my extended family, we tend to shop more at Amazon than either Target or Walmart. But it is nice to know that both Target and Walmart are putting this content out there. I welcome your own thoughts about their efforts.
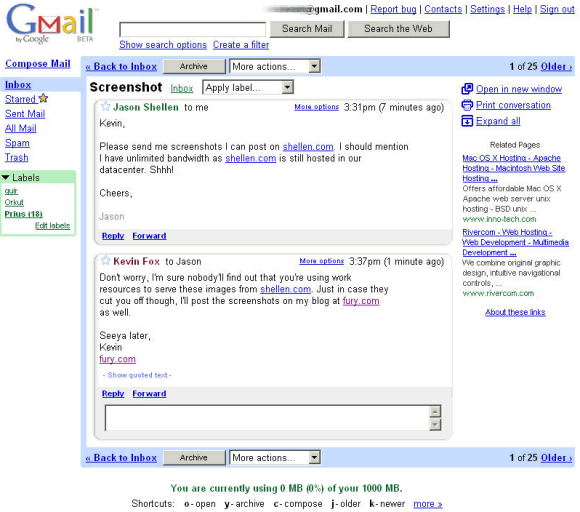


 This week the web has celebrated yet another of its
This week the web has celebrated yet another of its  Back in 1995, I was reminded of so-called “electronic books” that were a big deal. One of my favorites then was a 1993 book/disk package called
Back in 1995, I was reminded of so-called “electronic books” that were a big deal. One of my favorites then was a 1993 book/disk package called 
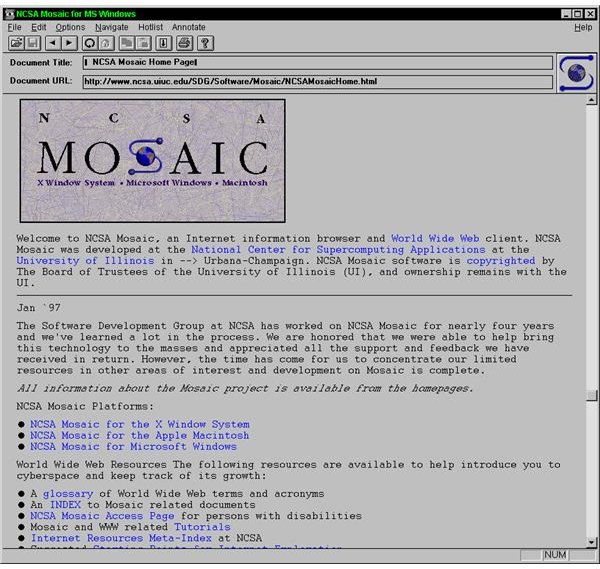
 Today we almost take it for granted that numerous enterprise software products have web front-end interfaces, not to mention all the SaaS products that speak native HTML. But back in the mid 1990s, vendors were still struggling with the web interface and trying it on. Cisco had its UniverCD (shown here), which was part CD-ROM and part website. The CD came with a copy of the Mosaic browser so you could look up the latest router firmware and download it online, and when I saw this back in the day I said it was a brilliant use of the two interfaces. Novell (ah, remember them?) had its Market Messenger CD ROM, which also combined the two. There were lots of other book/CD combo packages back then, including Frontier’s Cybersearch product. It had the entire Lycos (a precursor of Google) catalog on CD along with browser and on-ramp tools. Imagine putting the entire index of the Internet on a single CD. Of course, it would be instantly out of date but you can’t fault them for trying.
Today we almost take it for granted that numerous enterprise software products have web front-end interfaces, not to mention all the SaaS products that speak native HTML. But back in the mid 1990s, vendors were still struggling with the web interface and trying it on. Cisco had its UniverCD (shown here), which was part CD-ROM and part website. The CD came with a copy of the Mosaic browser so you could look up the latest router firmware and download it online, and when I saw this back in the day I said it was a brilliant use of the two interfaces. Novell (ah, remember them?) had its Market Messenger CD ROM, which also combined the two. There were lots of other book/CD combo packages back then, including Frontier’s Cybersearch product. It had the entire Lycos (a precursor of Google) catalog on CD along with browser and on-ramp tools. Imagine putting the entire index of the Internet on a single CD. Of course, it would be instantly out of date but you can’t fault them for trying. With the number of coding for cash contests, popularly called hackathons, exploding, now might be the time that you should consider spending part of your weekend or an evening participating, even if you aren’t a total coder. Indeed, if you are one of the growing number of citizen developers, you might be more valuable to your team than someone who can spew out tons of Ruby or Perl scripts on demand. I spoke to several hackathon participants at the QuickBase EMPOWER user conference last month to get their perspective. You can
With the number of coding for cash contests, popularly called hackathons, exploding, now might be the time that you should consider spending part of your weekend or an evening participating, even if you aren’t a total coder. Indeed, if you are one of the growing number of citizen developers, you might be more valuable to your team than someone who can spew out tons of Ruby or Perl scripts on demand. I spoke to several hackathon participants at the QuickBase EMPOWER user conference last month to get their perspective. You can