A startup here in St. Louis is trying to marry the analytics of the web with the practice of addiction counseling and psychotherapy. In doing so, they are trying to bring the methods of Moneyball to improve therapeutic outcomes. It is an interesting idea, to be sure.
The firm is called Takoda, and it is the work of several people: David Patterson Silver Wolf, an academic researcher; Ken Zheng, their business manager; Josh Fischer, their co-founder and CTO; and Jake Webb, their web developer. I spoke to Fischer who works full time for Bayer, and supports Takoda on his own time as they bootstrap the venture. “It is hard to put all the various pieces together in a single company, which is probably why no one else has tried to do this before,” he told me recently.
The idea is to measure therapists based on patient performance during treatment, just like Moneyball measured runs delivered by each baseball player as their performance measurement. But unlike baseball, there is no single metric that everyone has created, certainly not as obvious as RBIs or homers.
We are at a unique time in the healthcare industrial complex today. Everyone has multiple electronic health records that are stored in vast digital coffins; so named because this is where data usually goes to die. Even if we see mostly doctors in a single practice group, chances are our electronic medical records are stored in various data silos all over the place, without the ability to link them together in any meaningful fashion.
On top of this, the vast majority of therapists have their own paper-based data coffins: file cabinets full of treatment notes that are rarely consulted again. Takoda is trying to open these repositories, without breaching any patient data privacy or HIPAA regulations.
Part of the problem is that when someone seeks treatment, they don’t necessary learn how to get better or move beyond their addiction issues while they are in their therapist’s office. They have to do this on their own time, interacting with their families and friends, in their own communities and environment.
Another part of the problem is in how we select a therapist to see for the first time. Often, we get a personal referral, or else we hear about a particular office practice. When we walk in the door, we are usually assigned a therapist based on who is “up” – meaning the next person who has the lightest caseload or who is free at that particular moment when a patient walks in the door. This is how many retail sales operations work. The sole design criterion was to evenly distribute leads and potential customers. That is a bad idea and I will get to why in a moment.
Finally, the therapy industry uses two modalities that tend to make success difficult. One is that “good enough” is acceptable, rather than pursuing true excellence or curing a patient’s problem. When we seek medical care for something physically wrong with us, we can find the best surgeon, the best cardiologist, the best whatever. We look at their education, their experience, and so forth. Patients don’t have any way to do this when they seek counseling. The other issue is that therapists aren’t necessarily rewarded for excellence, and often practices let a lot of mediocre treatment slide. Both aren’t optimal, to be sure.
So along comes Takoda, who is trying to change how care is delivered, how success is measured, and whether we can match the right therapists to the patients to have the best treatment outcomes. That is a tall order, to be sure.
Takoda put together its analytics software and began building its product about a year ago. First they thought they could create something that is an add-on to the electronic health systems already in use, but quickly realized that wasn’t going to be possible. They decided to work with a local clinic here. The clinic agreed to be a proving ground for the technology and see if their methods work. They picked this clinic for geographic convenience (since the principals of the firm are also here in St. Louis) and because they already see numerous patients who are motivated to try to resolve their addiction issues. Also, the clinic accepts insurance payments. (Many therapists don’t deal with insurers at all.) They wanted insurers involved because many of them are moving in the direction of paying for therapy only if the provider can measure and show patient progress. While many insurers will pay for treatment, regardless of result, that is evolving. Finally, the company recognized that opioid abuse has slammed the therapy world, making treatment more difficult and challenging existing practices, so the industry is ripe for a change. Takoda recognizes that this is a niche market, but they had to start somewhere. “So we are going to reinvent this industry from the ground up,” said Fischer.
 So what does their system do? First off, it uses research to better match patients with therapists, rather than leave this to chance or the “ups” system that has been used for decades. Research has shown that matching gender and race between the two can help or hurt treatment outcomes, using very rough success measures.
So what does their system do? First off, it uses research to better match patients with therapists, rather than leave this to chance or the “ups” system that has been used for decades. Research has shown that matching gender and race between the two can help or hurt treatment outcomes, using very rough success measures.
Second, it builds in some pretty clever stuff, such as using your smartphone to create geofences around potentially risky locations for each individual patient, and providing a warning signal to encourage the patient to steer clear of these locations.
Finally, their system will “allow practice offices to see how their therapists are performing and look carefully at the demographics,” said Fischer. “We have to change the dynamic of how therapy care is being done and how therapists are rated, to better inform patients.”
It is too early to tell if Takoda will succeed or not, but if they do, the potential benefits are clear. Just like in Moneyball, where a poorly-performing team won more games, they hope to see a transformation in the therapy world with a lot more patient “wins” too.
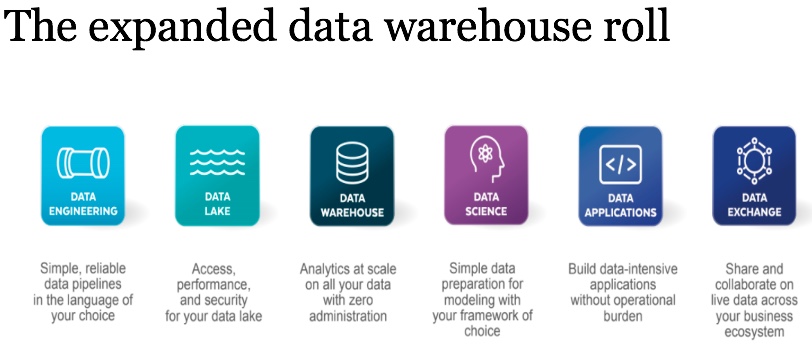 In today’s changing times, tech companies must renew their focus on customers, and use their data effectively to create a holistic, 360-degree view of those customers. With this view in place, they can both improve the customer experience and better inform product development in order to attract new customers and retain existing customers. Facing fragmented data, slow and fragile data pipelines, growing demands and increasing costs, legacy data warehouse solutions are no longer sufficient. Enter next gen Cloud Data Platforms. With integrated data and seamless sharing, tech companies can now serve real-time analytics, scale up operations, and enhance the customer experience. This will take you to the slide deck for an IDG webinar that I did for Snowflake.
In today’s changing times, tech companies must renew their focus on customers, and use their data effectively to create a holistic, 360-degree view of those customers. With this view in place, they can both improve the customer experience and better inform product development in order to attract new customers and retain existing customers. Facing fragmented data, slow and fragile data pipelines, growing demands and increasing costs, legacy data warehouse solutions are no longer sufficient. Enter next gen Cloud Data Platforms. With integrated data and seamless sharing, tech companies can now serve real-time analytics, scale up operations, and enhance the customer experience. This will take you to the slide deck for an IDG webinar that I did for Snowflake.

 Jonas started working on this many years ago at IBM. He is trying to disrupt the entity resolution market and eventually spun out Senzing with his tool. The goal is that you have all this data and you want to link it together, eliminate or find duplicates, or near-duplicates. Take our criminal, who is going to rent a truck, buy fuel oil and fertilizer, and so forth. He does so using the sample identities shown at the bottom of the graphic. Senzing’s software can parse all this data and within a matter of a few minutes, figure out who Bob Smith really is. In effect, they merge all the different channels of information into a single, coherent whole, so you can make better decisions.
Jonas started working on this many years ago at IBM. He is trying to disrupt the entity resolution market and eventually spun out Senzing with his tool. The goal is that you have all this data and you want to link it together, eliminate or find duplicates, or near-duplicates. Take our criminal, who is going to rent a truck, buy fuel oil and fertilizer, and so forth. He does so using the sample identities shown at the bottom of the graphic. Senzing’s software can parse all this data and within a matter of a few minutes, figure out who Bob Smith really is. In effect, they merge all the different channels of information into a single, coherent whole, so you can make better decisions.

 In the intervening years since that story, tracking technology has gotten better and Internet privacy has all but effectively disappeared. At the DEFCON trade show a few weeks ago in Vegas, researchers presented a paper on how easy it can be to track down folks based on their digital breadcrumbs. The researchers set up a phony marketing consulting firm and requested anonymous clickstream data to analyze. They were able to actually tie real users to the data through a series of well-known tricks, described in this
In the intervening years since that story, tracking technology has gotten better and Internet privacy has all but effectively disappeared. At the DEFCON trade show a few weeks ago in Vegas, researchers presented a paper on how easy it can be to track down folks based on their digital breadcrumbs. The researchers set up a phony marketing consulting firm and requested anonymous clickstream data to analyze. They were able to actually tie real users to the data through a series of well-known tricks, described in this 
 The three are Tesla, Express Scripts, and the Washington Post. It is just mere happenstance that they also make cars, manage prescription benefits and publish a newspaper. Software lies at the heart of each company, as much as a Google or a Microsoft.
The three are Tesla, Express Scripts, and the Washington Post. It is just mere happenstance that they also make cars, manage prescription benefits and publish a newspaper. Software lies at the heart of each company, as much as a Google or a Microsoft.