the fall of 2016, a set of attacks was launched using a clever exploit, by building an automated criminal collection of Internet-connected webcams and digital video recorders. Subsequently labeled “Mirai,” this botnet has been the source of a series of distributed denial of service (DDoS) attacks on numerous notable Internet destinations such as security journalist Brian Krebs’ site, a German ISP, and the Dyn.com domain name services that is used by many large-scale online companies.
Until Mirai came along, the vast majority of DDoS attacks were done using malware-infected Windows PCs, commandeered by criminals who could harness this collected computing power and control them remotely. But Mirai has changed all of that: the sheer numbers involved and the magnitude of damages inflicted on its targets has made Mirai a potent criminal force.
There are many things to learn from construction of its malware and its leverage of various IoT embedded devices. Let’s talk about the timeline of the destruction it has already accomplished, how Mirai was initially detected, and what IT managers need to know about defending their networks against some of the methods it used in its attacks.
Timeline: What actually happened?
Mirai has been in the news for a number of events from last fall. What is clear as you examine this timeline is how it has became increasingly more potent and dangerous as it was used against various online businesses.
- Sept 20: Brian Krebs
On September 20th Brian Krebs’ web servers became the target of one of the largest DDoS attacks ever recorded—between 600 billion and 700 billion bits per second. To give you an idea of the magnitude here, this level of traffic is almost half a percent of the Internet’s entire capacity. What makes this even more impressive is that these data rates were sustained for hours at a time against Krebs’ websites.
DDoS attacks are brute force: a collection of computers sends streams of automated TCP/IP traffic directed at a specific web destination. When the traffic reaches a certain volume, it can overwhelm and shut down this targeted server. An enterprise has to filter out the malicious traffic or otherwise divert it away from its network to bring its servers back online.
This wasn’t Krebs’ first DDoS attack: indeed, over the past several years, he has experienced hundreds of them. But it certainly was the biggest. According to Akamai, the Krebs’ attacks were launched by 24,000 systems infected with Mirai. During September, five attacks hit Krebs, ranging from 123 to 623 Gbps.
To better defend himself, he had been using the content delivery network Akamai to filter out the attacks. And for the most part, they were able to repel these earlier DDoS efforts. But the 9/20 attacks contained so much traffic that after several days Akamai had to throw in the virtual towel, and admit defeat. This meant that Krebs’ websites were offline for a few days, until he was able to move his protection to Google’s Project Shield. This is a free invitation-only program that is designed to help independent news sites stay up and running. So far Google’s efforts seem to be working and keeping his website up and running.
- Oct 1: source code for Mirai released on GitHub
The attack on Krebs was a great proof of concept, but the folks behind Mirai took things a step further. A few weeks later, a person going by “Anna_Senpai” posted the code for Mirai online, where it since has been downloaded thousands of times from various sources, including GitHub. The name refers to a Japanese anime character that is a law enforcer of sorts. The word Mirai is also Japanese for future. This further spreads the botnet infection as more criminals begin using the tool to assemble their own botnet armies.
- Oct 21: Dyn attack
Then in late October another huge attack was launched on Dyn, who provides domain name services (DNS) for a variety of large-scale customers such as GitHb, Twitter, Netflix, AirBnB and hundreds of others. These services are akin to an Internet phone book: when you request a particular website, such as Google.com, it routes your request to a particular TCP/IP address for Google’s webservers to respond. Without these naming services, your request goes nowhere. The Mirai attack used 100,000 unique IP addresses, a big step up from the earlier one on Krebs. Dyn has multiple data centers around the world, and there were three attempted attacks over the course of the day. The first two brought part of its operations down, meaning that Internet users couldn’t access the websites of certain Dyn customers. The third attack was thwarted by Dyn’s IT staff.
More information from Flashpoint here:
https://www.flashpoint-intel.com/mirai-botnet-linked-dyn-dns-ddos-attacks/
- Nov 1: Liberia’s Internet connection is taken offline
The Mirai botnet also brought down the entire Internet connection for Liberia in late October/early November. The attack was targeted at the two fiber companies that own the country’s Internet connections. These companies manage the link to a massive undersea cable that runs around the African continent, connecting other countries together. One possible reason for Liberia being targeted is its single fiber cable connection, and the fact that the Mirai botnet can overwhelm the connection with a 500 Gbps traffic flood.
- Nov 30: Deutsche Telekom
Then, in late November more than 900,000 customers of German ISP Deutsche Telekom (DT) were knocked offline after their Internet routers got infected by a new variant of the Mirai malware. The Mirai code seen in this attack has been modified with two important features: First, it has expanded its scope to exploit a security flaw in specific routers made by Zyxel and Speedport to allow remote code execution. These routers have been sold to numerous German customers, which is why DT was affected so severely. Second, this new strain of Mirai now scans the entire Internet looking for all potential devices that could be compromised.
- Mirai is still continuing
These are just the most noteworthy attacks to date. Given the size and effect, Mirai continues to be deployed for a variety of targets. Security researchers MalwareTech.com have set up this Twitter account to keep track of these attacks in near real-time, where you can see several attacks occur daily:
https://twitter.com/MiraiAttacks
How was Mirai first detected?
September 2016 was the month when a series of IoT-based botnets were detected by a variety of security researchers, most notably Sucuri and Flashpoint. Sucuri published several blog posts that described their investigations of several botnets that added up to a collection of more than 45,000 individual IP addresses. (Note that is about twice the number of origins first experienced by Krebs.) The botnets were able to pull off an attack on one of their customers that reached 120,000 requests per second. Sucuri’s customer was concerned because the level of the attack was so large that they couldn’t fight it off, even using Amazon and Google clouds to spin up larger virtual machines to defend themselves. This was similar to what happened with Krebs trying to use Akamai’s defenses.
The Sucuri assessment found three different types of endpoints that made up the attack on their customer: webcams, home routers, and compromised enterprise web servers. They found eight major home router brands that were part of the botnet, with the majority of the total IP addresses coming from Huawei brands. Many of these routers were located in Spanish-speaking countries, but there were plenty of compromised routers located all around the world. This geographic diversity is one of the reasons why Mirai was both so powerful and so hard to defend.
Pic: https://blog.sucuri.net/wp-content/uploads/2016/08/chart_home-router-botnet-map.png
Flashpoint found subsequent compromised devices by scanning Internet traffic on TCP port 7547, according to their researchers. They say there are several million other vulnerable devices in other countries, including Brazil and the UK. The latest Mirai variant is likely an attempt by one of the existing Mirai botmasters to expand the number of infected devices under their control. According to BadCyber.com, part of the problem is that DT who was initially targeted in November does not appear to have followed the best practice of blocking the rest of the world from remotely managing these devices.
Lessons for IT managers
The Mirai botnet has developed quickly as a major threat that will require a combination of methods to defend against its massive traffic volumes that can overwhelm even the most capable web servers. Here are several suggestions for IT and security managers.
First, have a DDoS strategy ahead of time. If you thought your company wasn’t that important, you need to forget that security-by-obscurity plan and come up with something more definitive. Anyone can become a target, and now is the time to plan appropriate measures. Flashpoint has some suggestions here that are worth reading.
Now is the time to examine how you obtain your DNS services. One of the problems for Dyn customers is that they didn’t make use of a secondary DNS provider, or didn’t configure their DNS servers to use more than one of Dyn’s data centers. Reconfiguring their servers took time and made the Mirai attack last longer. Some large online companies are now using both Dyn and other DNS providers (such as OpenDNS or easyDNS, for example) for redundant operations. This is a good strategy in case of future DNS-based attacks.
Flashpoint suggests you employ Anycast DNS as your provider. This has two benefits: first, it can spread the attacking botnet requests across a distributed network, lessening the burden on each individual machine. Second, it can also speed up DNS responses, making your Internet visitors happier when pages load more quickly.
Another strategy is to regularly check your routers for inadvertent DNS changes, what is called DNS hijacking. F-Secure has a simple and free tool that can determine if your routers’ DNS settings have been tampered with, and that only takes a few seconds to find out for each router. While this could be tedious, at least home routers should be checked with this tool.
One early strategy was to simply reboot your routers, since Mirai is memory-resident and rebooting removes the infection. While that initially will work, it isn’t a good longer-term solution, since the criminals have perfected scanning techniques to re-infect your router if it is still using the default passwords in their hit list. So of course, the next step is to change these defaults, then reboot again.
Find any unchanged factory default passwords on any network equipment and change them immediately. These passwords were the reason why Mirai was able to collect so many endpoint IoT webcams and routers to begin with. The F-Secure tool can help with home routers, but a more complete program should be put in place to ensure that all critical network infrastructure has appropriately complex and unique passwords going forward.
Make sure your network forensics are in order. You should be able to capture the attack traffic so you can analyze what happened and who is targeting you. Mirai made use of an exploit on TCP port 7547 to connect to those home routers, so add a detection rule to monitor that port especially. Also, make sure that legitimate traffic is not counted or recorded in your logs. Part of this is in understanding metrics of your normal traffic baselines too.
Finally, it may be time to consider a content delivery network provider to handle your peak traffic loads. As you investigate your historic traffic patterns, you can see if your webservers are stretched too thinly or if you need to purchase additional load balancing or content delivery networks to improvement performance.
 Many website operators have wrestled with the decision to move all their web infrastructure to support HTTPS protocols. The upside is obvious: better protection and a more secure pathway between browser and server. However, it isn’t all that easy to make the switch. In this piece that I wrote for IBM’s Security Intelligence blog, I bring up the case study of The Guardian’s website and what they did to make the transition. It took them more than a year and a lot of careful planning before they could fully support HTTPS.
Many website operators have wrestled with the decision to move all their web infrastructure to support HTTPS protocols. The upside is obvious: better protection and a more secure pathway between browser and server. However, it isn’t all that easy to make the switch. In this piece that I wrote for IBM’s Security Intelligence blog, I bring up the case study of The Guardian’s website and what they did to make the transition. It took them more than a year and a lot of careful planning before they could fully support HTTPS.
 Going back to our podcast, Paul and I next pick up on the
Going back to our podcast, Paul and I next pick up on the 


 Remember those halcyon days of Pets.com and its spokes-puppet? Seems like a long time ago.
Remember those halcyon days of Pets.com and its spokes-puppet? Seems like a long time ago. Both Paul and I have known Sam Whitmore since all three were at PC Week (now eWeek) back in the go-go 1980s. Since 1998, Sam has been running his own consultancy for PR firms, called
Both Paul and I have known Sam Whitmore since all three were at PC Week (now eWeek) back in the go-go 1980s. Since 1998, Sam has been running his own consultancy for PR firms, called 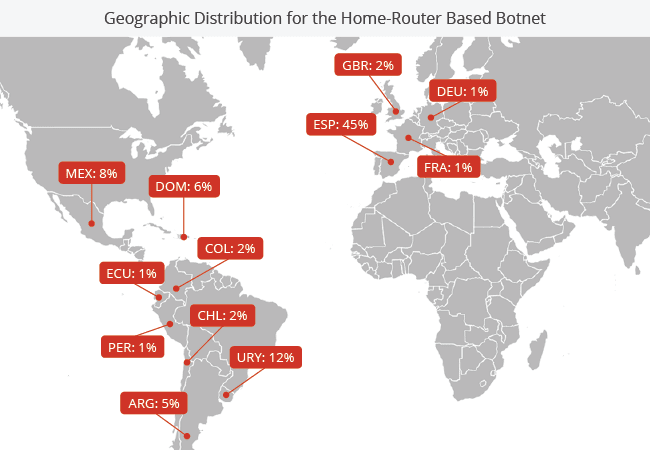{kind=link}