If you believe the 2020 elections experienced massive fraud, or that electronic voting machines were running some software from space, then please skip this post. If you believe otherwise, then I would urge you to read my thoughts.
I was party to a massive elections fraud back in the 1970s, when I lived and worked for the city of Albany NY. Albany at the time (and still today!) was under the grip of a powerful Democratic machine, and as a city employee I was told as election day approached that I will vote, and that I will vote the Democratic party line. If I didn’t show up, or if I strayed into supporting GOP candidates, I would lose my job. Whether or not everyone’s votes were being monitored, I wasn’t going to risk it, especially as this was my first job out of college. I can’t prove anything, and my recollection might be fuzzy, but there was no denying that the city spent decades in the iron grip of this political machine.
I am telling you this because I have spent a lot of time researching voting fraud over the past several years, and can tell you that our elections have come a long way since my Albany days. I based this on first-hand knowledge, having spoken to IT managers at state offices, election researchers, and others who are in the know. Let me first present a few links for you to establish some bona fides.
First up is Alex Halderman’s analysis of the 2020 voting irregularities in Antrim County, Mich. This was the scene of numerous recounts — five of them — and the source of a lot of conspiracy theories. If you read Alex’s paper, you will see that many of these theories were easily explained by more obvious error sources, namely humans. I have met Alex in person and interviewed him on this topic and he is a very sharp guy. His paper concludes: there is “strong empirical evidence that there are no significant errors in Antrim’s final presidential results, including due to any scanning mishap.”
Copies of the voting machine software eventually found their way to Mike Lindell and his bogus “CyberSecurity Summit” that he held in South Dakota in the summer of 2021. One of the attendees at that conference was a long-time colleague Bill Alderson. He was interested in getting the promised reward of $5M to prove voting irregularities. You can watch Bill’s interview with local TV news where he unequivocally states that the data claimed by Lindell was a nothing burger (he had more colorful language when I spoke to him this week). In other words, there was no fraud, no evidence, nada. Bill never got a dime for his troubles, BTW.
There was several other county voting offices who were invaded by so-called security analysts looking for fraud. But they ended up doing their own fraud — and are now being charged for this by various legal efforts. These folks obtained copies of similar machine software and vote tally data cards. One of these locales was Coffee County, Geo. The AP ran this story about what happened last September and there was plenty of video footage, along with the data cards shown in the photo below that were given to these analysts. (Here is an excellent analysis from Lawfare too.)

As the 2020 election was happening, I was part of the CISA press group who was on the phone interviewing various officials on November 3rd. Granted, CISA had their own horn to toot, but from the evidence that I saw, the election happened without any major troubles. Yes, Chris Krebs lost his job shortly thereafter, which should tell you something about his integrity.
One lie that I hear often is the manipulation of mail-in ballots was done in a such way to swing the vote totals. Here is another data point: Colorado has been running universal mail-in ballots (meaning every registered voter gets one by mail, whether they want to use it or not is up to them). For years they have running fair and accurate elections. Neither major party had a problem with that, until the more recent elections. Here is a link to their info page, just to give you an idea of what they do. (Many states have had pre-Covid universal mail-in operations, BTW.)
Now, I warned you — here comes the hard part for me to write about. We are approaching a very dangerous time in our country. There are many people who believe this massive voting fraud happened, despite various genuine IT consultants’ evidence to the contrary. I am not here to try to convince them of the error of their ways.
But let’s talk about something that I find even more distressing. Please check out this recent Politico post on what happened last week at the Vegas BlackHat conference. To provide some context, each year this hacking event features various “villages” where a bunch of attendees come to try to break stuff, in this particular case voting machines. (I wrote about the 2020 election village DEFCON event for Avast here.) Given the state of our society right now, this year they put on some extra physical security for the event. And if you believe Politico’s reporting is accurate, it is very chilling to see.
By now many of us have heard about how elections officials have been threatened both at home and at their offices. According to a March 2022 study from NYU’s Brennan Center for Justice, one in six election workers have experienced threats because of their job, and 77% said those threats had increased in recent years. Many have quit the field entirely.
That is bad enough, but now these threats have blossomed beyond the folks running the elections to include digital security researchers that are looking into election and voting-related matters. And I am thinking about my early Albany experience. Yes, we have issues with vote counting and certainly there is plenty of mistakes made over the years. But to annoy and threaten the people who in many cases volunteer their time and do their civic duty and claim they have evil intent, just because the election didn’t go your way is a horse of a different color.
Where do we go from here? I don’t know. But thanks for reading this far.

 If you live there, for the last several years you can have your packages delivered to one of now 1,000 public lockers that are all over the island. If you have ever used the lockers that Amazon has at Whole Foods or one of its other storefronts, you get the idea. It is a wall of lockers of various sizes with a computer controlling access. Once you authenticate yourself, a door opens and the package is revealed. The lockers are built and operated by Pick Network and are called the Locker Alliance Network (which sounds vaguely Terminator-ish but let’s move on). You choose the locker installation nearest to your home or office or wherever you happen to be, and the delivery company will get the package there.
If you live there, for the last several years you can have your packages delivered to one of now 1,000 public lockers that are all over the island. If you have ever used the lockers that Amazon has at Whole Foods or one of its other storefronts, you get the idea. It is a wall of lockers of various sizes with a computer controlling access. Once you authenticate yourself, a door opens and the package is revealed. The lockers are built and operated by Pick Network and are called the Locker Alliance Network (which sounds vaguely Terminator-ish but let’s move on). You choose the locker installation nearest to your home or office or wherever you happen to be, and the delivery company will get the package there.  Longtime freelancing colleague Pam Baker’s
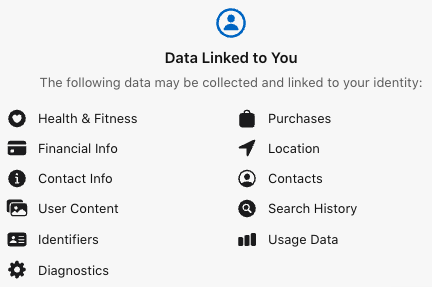
Longtime freelancing colleague Pam Baker’s  Last week Shou Chew, the CEO of the American TikTok, was called on the US House hearing room carpet. Combining the current anti-China paranoia with social media crimes against teenagers was a potent political mix that brought a tremendous amount of bipartisan angst. The five hour hearing was attended by seemingly the entire House membership, and for me it was noteworthy in that almost none of the members were folks that I have ever heard of, but all managed to ask unanswerable questions that they demanded simple yes or no answers so they could save time for their own take.
Last week Shou Chew, the CEO of the American TikTok, was called on the US House hearing room carpet. Combining the current anti-China paranoia with social media crimes against teenagers was a potent political mix that brought a tremendous amount of bipartisan angst. The five hour hearing was attended by seemingly the entire House membership, and for me it was noteworthy in that almost none of the members were folks that I have ever heard of, but all managed to ask unanswerable questions that they demanded simple yes or no answers so they could save time for their own take. The relationship between TikTok and its parent company was explored in detail in this
The relationship between TikTok and its parent company was explored in detail in this