I have been involved in tech for most of my professional career, but only recently did I realize its role in literally saving my life. Maybe that is too dramatic. Let’s just say that nothing dire has happened to me, I am healthy and doing fine. This realization has come from taking a longer view of my recent past and the role that tech has played in keeping me healthy.
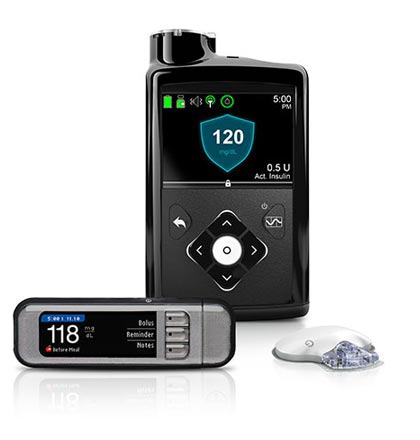
 Let me tell you how this has come about. Not too long ago, I read this article in The Atlantic about people with type 1 diabetes who have taken to hacking the firmware and software running their glucose pumps, such as the one pictured here. For those of you that don’t know the background, T1D folks are typically dealing with their illness from an early age, hence they are usually called “juvenile diabetics.” This occurs with problems with their pancreas producing the necessary insulin to metabolize food.
Let me tell you how this has come about. Not too long ago, I read this article in The Atlantic about people with type 1 diabetes who have taken to hacking the firmware and software running their glucose pumps, such as the one pictured here. For those of you that don’t know the background, T1D folks are typically dealing with their illness from an early age, hence they are usually called “juvenile diabetics.” This occurs with problems with their pancreas producing the necessary insulin to metabolize food.
T1D’s typically take insulin in one of two broad ways: either by injection or by using a pump that they wear 24/7. Monitoring their glucose levels is either done with manual chemical tests or by the pump doing the tests periodically.
Every T1D relies on a great deal of technology to manage their disease and their treatment. They have to be extremely careful with what they eat, when they eat, and how they exercise. A cup of coffee can ruin their day, and something else can literally put them in mortal danger.
That is what got me thinking of my own situation. As I said, my case is far less dire, but I never really looked at my overall health care. To take three instances: I take daily blood pressure meds, use a sleep apnea machine every night, and wear a hearing aid. All of these things are to manage various issues with my health. All of them are tech-related, and I am thankful that modern medicine has figured them out to mitigate my problems. I would not be as healthy as I am today without all of them. Sometimes I get sad about the various regimens, particularly as I have to lug the apnea machine aboard yet another international flight or remember to reorder my meds. Yet, I know that compared to T1D folks, my reliance on tech is far less than their situation.
I know a fair bit about T1D through an interesting story. It is actually how I met my wife Shirley many years ago: we were both volunteers at a JDRF bike fundraising event in Death Valley, even though neither of us has a direct family connection to the disease. I was supposed to ride the event and had raised a bunch of money (thanks to many of your kind donations, BTW) but broke my shoulder during a training ride. Fortunately, the JDRF folks running the event insisted that I should still come, and the rest, as they say, is history.
One of the T1D folks that I know is a former student of mine, who is part of the community of “loopers” that are hacking their insulin pumps. Over the past several months he has collected the necessary gear to get this to work. Let’s call him Adam (not his real name).
 Why is looping better than just using the normal pump controls? Mainly because you have better feedback and more precise control over insulin doses. “If you literally sat and watched your blood sugar 24/7 and were constantly making adjustments, sure you could get great control over your insulin levels. But it’s far easier to let the software do it for you, because it checks your levels every five minutes. In reality, I’m feeding my pump’s computer small pieces of data that is very commonly used in the T1D community for diabetes management. So it is no big deal.”
Why is looping better than just using the normal pump controls? Mainly because you have better feedback and more precise control over insulin doses. “If you literally sat and watched your blood sugar 24/7 and were constantly making adjustments, sure you could get great control over your insulin levels. But it’s far easier to let the software do it for you, because it checks your levels every five minutes. In reality, I’m feeding my pump’s computer small pieces of data that is very commonly used in the T1D community for diabetes management. So it is no big deal.”
Adam also told me he took about four days to get used to the setup and understand what the computer’s algorithms were doing for his insulin management. So much information is available online in various forums and documentation of different pieces of open source software that include projects such as Xdrip, Spike, OpenAPS, Nightscout, Loop, Tidepool, and Diasend. It is pretty remarkable what these folks are doing. As Adam says, “You need to be involved in your own care — but some of the stress in decision making is gone. Having a future prediction of your glucose level makes it easier to plan for the longer term and feel more confident.”
But looping has another big benefit, because it is monitoring you even when asleep. It also gives you a new perspective on your care, because you have to understand what the computer algorithms are doing in dispensing insulin. “The most powerful way to use an algorithm is when you combine the human and computer together — the algorithm is not learning. It’s just reusing well established rules, “ says Adam. “It’s pretty dumb without me and I’m way better off with it when we work together. That’s why I say that my setup is a thousand times better than what I had before. I have an astonishingly better tool in this fight.”
There are a few down sides: you do need to learn how to become your own system integrator, because there are different pieces you have to knit together. The pumps have firmware that could disable the looping: this was done for the patient’s protection, when it was found that some of them were hackable (at close distances, but still) and for their protection. If you upgrade your pump, your looping could be disabled.
You also need to have a paid Apple Developer account to put everything together, because the iPhone app that is used to connect his pump requires this developer-level access. “It is more than worth the $100 a year,” Adam told me. There are also Android solutions, but he has been an iPhone user for so long it didn’t make sense for him to switch.
Finally, looping is not legal, and not yet approved by the FDA. Many other countries have recognized this pattern of treatment, and the FDA is considering approval.
This is the way of the modern tech era, and how savvy patients have begun to take back control over their care. It is great that we can point to this example as a way that tech can literally save lives, and that patients today have such powerful tools at their disposal too. And the looping story hopefully should inspire you to take control over your own medical care.
 No computing professional wants to encounter a ransomware attack. But these six poor IT decisions can make that scenario more likely to occur. Ransoms are not the result of an isolated security incident but the consequence of a series of IT missteps. Moreover, it often exposes poor decision-making that indicates deeper management issues that must be fixed. In this article for HPE’s Enterprise.nxt website, I discuss how these missteps can be corrected before you are the subject to the next attack.
No computing professional wants to encounter a ransomware attack. But these six poor IT decisions can make that scenario more likely to occur. Ransoms are not the result of an isolated security incident but the consequence of a series of IT missteps. Moreover, it often exposes poor decision-making that indicates deeper management issues that must be fixed. In this article for HPE’s Enterprise.nxt website, I discuss how these missteps can be corrected before you are the subject to the next attack.



 The threat of fileless malware and its potential to harm enterprises is growing. Fileless malware leverages what threat actors call “living off the land,” meaning the malware uses code that already exists on the average Windows computer. When you think about the modern Windows setup, this is a lot of code: PowerShell, Windows Management Instrumentation (WMI), Visual Basic (VB), Windows Registry keys that have actionable data, the .NET framework, etc. Malware doesn’t have to drop a file to use these programs for bad intentions.
The threat of fileless malware and its potential to harm enterprises is growing. Fileless malware leverages what threat actors call “living off the land,” meaning the malware uses code that already exists on the average Windows computer. When you think about the modern Windows setup, this is a lot of code: PowerShell, Windows Management Instrumentation (WMI), Visual Basic (VB), Windows Registry keys that have actionable data, the .NET framework, etc. Malware doesn’t have to drop a file to use these programs for bad intentions.
 Earlier this month, president of RSA, Rohit Ghai, opened the RSA Conference in San Francisco with some stirring words about understanding the trust landscape. The talk is both encouraging and depressing, for what it offers and for how far we have yet to go to realize this vision completely.
Earlier this month, president of RSA, Rohit Ghai, opened the RSA Conference in San Francisco with some stirring words about understanding the trust landscape. The talk is both encouraging and depressing, for what it offers and for how far we have yet to go to realize this vision completely.