It isn’t often that engineers blog about deliberately failing at their jobs, but for Cory Bennett and Ariel Tseitlin, writing in Netflix’ TechBlog last month, it is an interesting idea. As you virtualize more of your datacenter infrastructure and develop more cloud-based apps, understanding where the failure points are and how to recover from them will be key. Knowing what VMs are dependent on others and how to restart particular services in the appropriate order will take some careful planning. What Netflix has done is to continually test its large Amazon Web Services infrastructure with what it calls “Chaos Monkey”.
The duo created the testing service, and posted that “We have found that the best defense against major unexpected failures is to fail often. By frequently causing failures, we force our services to be built in a way that is more resilient.” Even if your cloud infrastructure isn’t the size of Netflix, it is still worth considering.
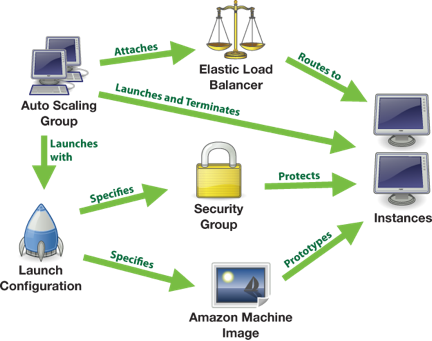 Chaos Monkey is a service that seeks out Amazon’s Auto Scaling Groups (ASGs) and terminates the various virtual machines inside a particular group. Netflix released the source code on Github and claims that it can be designed for other cloud providers with a minimum of effort. There is a documentation wiki for the tool which can be found here. (Netflix has the flow diagram here that shows the relationship of the various services.)
Chaos Monkey is a service that seeks out Amazon’s Auto Scaling Groups (ASGs) and terminates the various virtual machines inside a particular group. Netflix released the source code on Github and claims that it can be designed for other cloud providers with a minimum of effort. There is a documentation wiki for the tool which can be found here. (Netflix has the flow diagram here that shows the relationship of the various services.)
If you aren’t using Amazon’s ASGs, this might be a motivation to try them out. The service is a powerful automation tool and can help you run new (or terminate unneeded) instances when your load changes quickly. Even if your cloud deployment is relatively modest, at some point your demand will grow and you don’t want to depend on your coding skills or being awake when this happens and have to respond to these changes. ASGs makes it easier to juggle the various AWS service offerings.
Chaos Monkey is the next step in your cloud evolution and automation. The idea is to run this automated routine during a limited set of hours with the intent that engineers will be alert and able to respond to the failures that it generates in your cloud-based services. It is a dandy of an idea.
“Over the last year Chaos Monkey has terminated over 65,000 instances running in our production and testing environments. Most of the time nobody notices, but we continue to find surprises caused by Chaos Monkey which allows us to isolate and resolve them so they don’t happen again,” says Bennett and Tseitlin.
As the posters state, “If your application can’t tolerate an instance failure would you rather find out by being paged at 3am or when you’re in the office and have had your morning coffee?” Very true.